

2·
4 months agoI don’t know if it’s your cup of tea, but Neovide provides smooth scrolling at arbitrary refresh rates. (It’s a graphical frontend for Neovim, my IDE of choice.)
Programmer in NYC
I don’t know if it’s your cup of tea, but Neovide provides smooth scrolling at arbitrary refresh rates. (It’s a graphical frontend for Neovim, my IDE of choice.)
If I’m doing more than one cracking two together is best. For the last one, countertop.
I get the flat, inside-the-sink idea. But I’d want to clean either way, and I clean the counters more often than I clean the sides of the sink.
For some more detail see https://dev.to/martiliones/how-i-got-linus-torvalds-in-my-contributors-on-github-3k4g

Oh, I didn’t know about the Teflon coating. From what I just read virtually all razor blades - both double-edged and cartridge - have PTFE coating. (Where PTFE is a PFAS compound, and PFAS is the family of compounds also known as Teflon.) But there is some hope for an alternative someday. https://www.pcimag.com/articles/111660-a-close-shave
So I guess I would say stick with double-edged. Or maybe electric would be better specifically with respect to water pollution? Since that’s the big issue with PFAS. I don’t know, just a guess.

I did not realize nano implemented syntax highlighting!
Oh this is just the thing for playing bard, and casting “vicious mockery” several times per combat
The justification for invading Iraq was a claim that they were developing nuclear weapons. It was well known at the time that the evidence was flimsy, and that even if true it was a flimsy excuse for an invasion. The main piece of evidence was an intercepted shipment of aluminum tubes that were soon shown to have nothing to do with a nuclear program. (See https://en.m.wikipedia.org/wiki/Iraqi_aluminum_tubes). That one is not a conspiracy theory.
It looks like there is at least one work-in-pprogress implementation. I found a Hacker News comment that points to github.com/n0-computer/iroh
Yeah, that makes a lot of sense. If the thinking is that AI learning from others’ works is analogous to humans learning from others’ works then the logical conclusion is that AI is an independent creative, non-human entity. And there is precedent that works created by non-humans cannot be copyrighted. (I’m guessing this is what you are thinking, I just wanted to think it out for myself.)
I’ve been thinking about this issue as two opposing viewpoints:
The logic-in-a-vacuum viewpoint says that AI learning from others’ works is analogous to humans learning from others works. If one is not restricted by copyright, neither should the other be.
The pragmatic viewpoint says that AI imperils human creators, and it’s beneficial to society to put restrictions on its use.
I think historically that kind of pragmatic viewpoint has been steamrolled by the utility of a new technology. But maybe if AI work is not copyrightable that could help somewhat to mitigate screwing people over.
That sounds like a good learning project to me. I think there are two approaches you might take: web scraping, or an API client.
My guess is that web scraping might be easier for getting started because scrapers are easy to set up, and you can find very good documentation. In that case I think Perl is a reasonable choice of language since you’re familiar with it, and I believe it has good scraping libraries. Personally I would go with Typescript since I’m familiar with it, it’s not hard (relatively speaking) to get started with, and I find static type checking helpful for guiding one to a correctly working program.
OTOH if you opt to make a Lemmy API client I think the best language choices are Typescript or Rust because that’s what Lemmy is written in. So you can import the existing API client code. Much as I love Rust, it has a steeper learning curve so I would suggest going with Typescript. The main difficulty with this option is that you might not find much documentation on how to write a custom Lemmy client.
Whatever you choose I find it very helpful to set up LSP integration in vim for whatever language you use, especially if you’re using a statically type-checked language. I’ll be a snob for just a second and say that now that programming support has generally moved to the portable LSP model the difference between vim+LSP and an IDE is that the IDE has a worse editor and a worse integrated terminal.
And there is also Nushell and similar projects. Nushell has a concept with the same purpose as jc where you can install Nushell frontend functions for familiar commands such that the frontends parse output into a structured format, and you also get Nushell auto-completions as part of the package. Some of those frontends are included by default.
As an example if you run ps you get output as a Nushell table where you can select columns, filter rows, etc. Or you can run ^ps to bypass the Nushell frontend and get the old output format.
Of course the trade-off is that Nushell wants to be your whole shell while jc drops into an existing shell.
I’m a fan! I don’t necessarily learn more than I would watching and reading at home. The main value for me is socializing and networking. Also I usually learn about some things I wouldn’t have sought out myself, but which are often interesting.
This is exactly why we have Reversed Polish Notation. When will people learn?
Oh goddammit! Why doesn’t PEMDAS prepare us for unary negation??
The problem is that the way PEMDAS is usually taught multiplication and division are supposed to have equal precedence. The acronym makes it look like multiplication comes before division, but you’re supposed to read MD and as one step. (The same goes for addition and subtraction so AS is also supposed to be one step.) It this example the division is left of the multiplication so because they have equal precedence (according to PEMDAS) the division applies first.
IMO it’s bad acronym design. It would be easier if multiplication did come before division because that is how everyone intuitively reads the acronym.
Maybe it should be PE(M/D)(A/S). But that version is tricky to pronounce. Or maybe there shouldn’t be an acronym at all.
The parentheses step only covers expressions inside parentheses. That’s 2 + 2 in this case. The times-2 part is outside the parentheses so it’s evaluated in a different step.
The comment from subignition explains that the phone’s answer, 16, is what you get by strictly following PEMDAS: the rule is that multiplication and division have the same precedence, and you evaluate them from left-to-right.
The calculator uses a different convention where either multiplication has higher priority than division, or where “implicit” multiplication has higher priority (where there is no multiply sign between adjacent expressions).

And also asking, how does it compare to a high-yield savings account?
That’s a very nice one! I also enjoy programming ligatures.
I use Cartograph CF. I like to use the handwriting style for built-in keywords. Those are common enough that I identify them by shape. The loopy handwriting helps me to skim over the keywords to focus on the words that are specific to each piece of code.
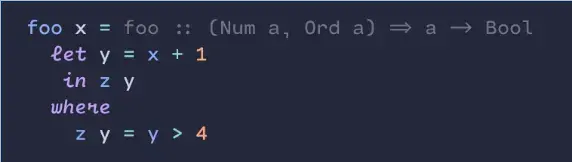
I wish more monospace fonts would use the “m” style from Ubuntu Mono. The middle leg is shortened which makes the glyph look less crowded.
It scrolls smoothly, it doesn’t snap line by line. Although once the scroll animation is complete the final positions of lines and columns do end up aligned to a grid.
Neovim (as opposed to Vim) is not limited to terminal rendering. It’s designed to be a UI-agnostic backend. It happens that the default frontend runs in a terminal.