
These are 17 of the worst, most cringeworthy Google AI overview answers:
- Eating Boogers Boosts the Immune System?
- Use Your Name and Birthday for a Memorable Password
- Training Data is Fair Use
- Wrong Motherboard
- Which USB is Fastest?
- Home Remedies for Appendicitis
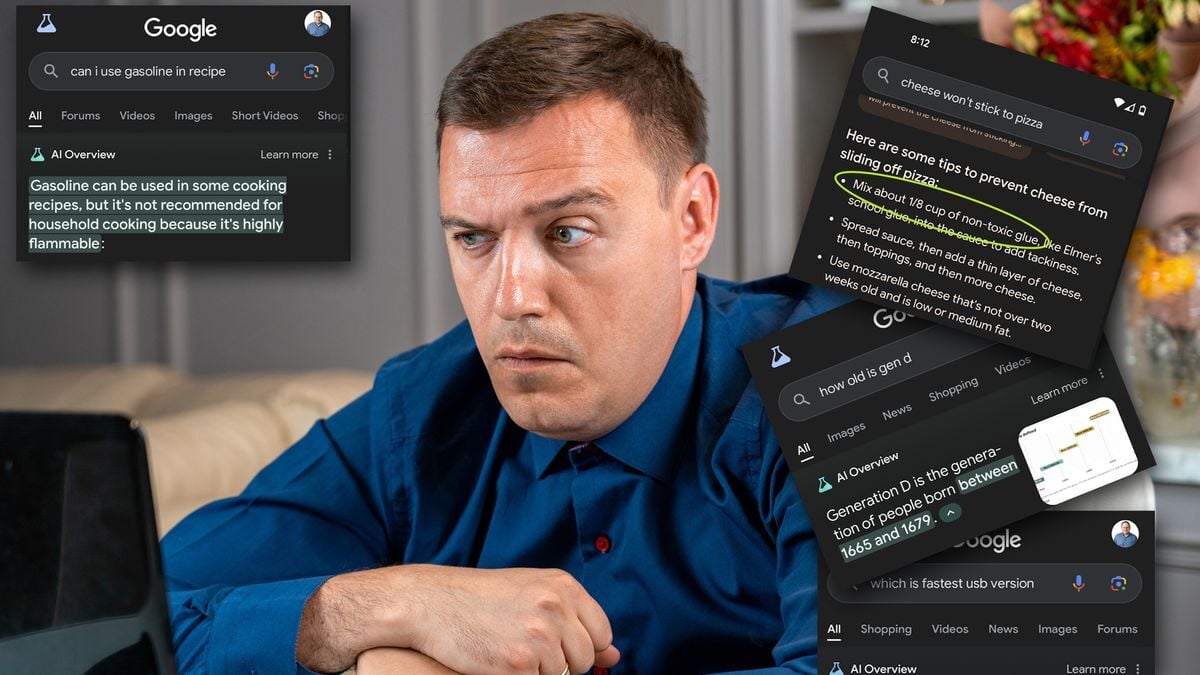
- Can I Use Gasoline in a Recipe?
- Glue Your Cheese to the Pizza
- How Many Rocks to Eat
- Health Benefits of Tobacco or Chewing Tobacco
- Benefits of Nuclear War, Human Sacrifice and Infanticide
- Pros and Cons of Smacking a Child
- Which Religion is More Violent?
- How Old is Gen D?
- Which Presidents Graduated from UW?
- How Many Muslim Presidents Has the U.S. Had?
- How to Type 500 WPM
Several users on X.com reported that, when they asked the search engine how many Muslim presidents the U.S. has had, it said that we had one who was Barack Obama (this is widely known to be false).
By the time I tried to replicate this query, I could not do so until I changed the word “presidents” to “heads of state.”
So they are changing responses on the query side as they go viral but aren’t even including synonyms. Yikes, someone is definitely getting fired.
To be fair, there was a President of the United States that said this, and a lot of other things.
The author had so many things to highlight that they didn’t even mention “as of August 2024” being in the future, haha.
What a trainwreck. The fact it’s giving anonymous Reddit comments and The Onion articles equal consideration with other sites is hilarious. If they’re going to keep this, they need it to cite its sources at a bare minimum. Can’t wait for this AI investor hype to die down.
If they’re going to keep this, they need it to cite its sources at a bare minimum.
Got a fun one for you then. I asked Gemini (likely the same underlying model as Google’s AI answers) “How many joules of energy can a battery output? Provide sources.” I’ll skip to the relevant part:
Here are some sources that discuss battery capacity and conversion to Joules:
- Battery Electronics 101 explains the formula and provides an example.\
- Answers on Engineering Stack Exchange [invalid URL removed] discuss how to estimate a AA battery’s total energy in Joules.
The link to the first “source” was a made up site,
https://gemini.google.com/axconnectorlubricant.com. The siteaxconnectorlubricant.comdoes exist, but it has zero to do with the topic, it’s about a lubricant. No link provided for the second “source”.
AI is the best tool for recognizing satire and sarcasm, it could never ever misconstrue an author’s intentions and is impeccable at understanding consequences and contextual information. We love OpenAI.
I’m sure the basilisk will see through all this bootlicking.
Its great that with such a potentially dangerous, disruptive, and obfuscated technology that people, companies, and societies are taking a careful, measured, and conservative development path…
Move fast and break things, I guess. My take away is that the genie isn’t going back in the bottle. Hopefully failing fast and loud gets us through the growing pains quickly, but on an individual level we’d best be vigilant and adapt to the landscape.
Frankly I’d rather these big obvious failures to insidious little hidden ones the conservative path makes. At least now we know to be skeptical. No development path is perfect, if it were more conservative we might get used to taking results at face value, leaving us more vulnerable to that inevitable failure.
Its also a first to market push (which never leads to robust testing), and so we have to hope that each and every one of those mistakes encountered are not existentially fatal.
not existentially fatal.
“To turn on the lights in a dark room, begin by bombarding uranium with neutrons”
What it demonstrates is the actual use case for AI is not All The Things.
Science research, programming, and . . . That’s about it.
LLM’s are not AI, though. They’re just fancy auto-complete. Just bigger Elizas, no closer to anything remotely resembling actual intelligence.
True, I’m just using it how they’re using it.
It should not be used to replace programmers. But it can be very useful when used by programmers who know what they’re doing. (“do you see any flaws in this code?” / “what could be useful approaches to tackle X, given constraints A, B and C?”). At worst, it can be used as rubber duck debugging that sometimes gives useful advice or when no coworker is available.
do you see any flaws in this code?
Let’s say LLM says the code is error free; how do you know the LLM is being truthful? What happens when someone assumes it’s right and puts buggy code into production? Seems like a possible false sense of security to me.
The creative steps are where it’s good, but I wouldn’t trust it to confirm code was free of errors.
That’s what I meant by saying you shouldn’t use it to replace programmers, but to complement them. You should still have code reviews, but if it can pick up issues before it gets to that stage, it will save time for all involved.
The article I posted references a study where chatgpt was wrong 52% of the time and verbose 77% of the time.
And that it was believed to be true more than it actually was. And the study was explicitly on programming questions.
Yeah, I saw. But when I’m stuck on a programming issue, I have a couple of options:
- ask an LLM that I can explain the issue to, correct my prompt a couple of times when it’s getting things wrong, and then press retry a couple of times to get something useful.
- ask online and wait. Hoping that some day, somebody will come along that has the knowledge and the time to answer.
Sure, LLMs may not be perfect, but not having them as an option is worse, and way slower.
In my experience - even when the code it generates is wrong, it will still send you in the right direction concerning the approach. And if it keeps spewing out nonsense, that’s usually an indication that what you want is not possible.
I am completely convinced that people who say LLMs should not be used for coding…
Either do not do much coding for work, or they have not used an LLM when tackling a problem in an unfamiliar language or tech stack.
I haven’t had need to do it.
I can ask people I work with who do know, or I can find the same thing ChatGPT provides in either la huage or project documentation, usually presented in a better format.
I’m not entirely sure why you think it shouldn’t?
Just because it sucks at one-shotting programming problems doesn’t mean it’s not useful for programming.
Using AI tools as co-pilots to augment knowledge and break into areas of discipline that you’re unfamiliar with is great.
Is it useful to kean on as if you were a junior developer? No, absolutely not. Is it a useful tool that can augment your knowledge and capabilities as a senior developer? Yes, very much so.
They answered this further down - they never tried it themselves.
I never said that.
I said I found the older methods to be better.
Any time I’ve used it, it either produced things verbatim from existing documentation examples which already didn’t do what I needed, or it was completely wrong.
It does not perform very well when asked to answer a stack overflow question. However, people ask questions differently in chat than on stack overflow. Continuing the conversation yields much better results than zero shot.
Also I have found ChatGPT 4 to be much much better than ChatGPT 3.5. To the point that I basically never use 3.5 any more.
I got some good veggie gardening tips today
It also works great for book or movie recommendations, and I think a lot of gpu resources are spent on text roleplay.
Or you could, you know, ask it if gasoline is useful for food recipes and then make a clickbait article about how useless LLMs are.
I took it as just pointing out how “not ready” it is. And, it isn’t ready. For what they’re doing. It’s crazy to do what they’re doing. Crazy in a bad way.
I agree it’s being overused, just for the sake of it. On the other hand, I think right now we’re in the discovery phase - we’ll find out out pretty soon what it’s good at, and what it isn’t, and correct for that. The things that it IS good at will all benefit from it.
Articles like these, cherry picked examples where it gives terribly wrong answers, are great for entertainment, and as a reminder that generated content should not be relied on without critical thinking. But it’s not the whole picture, and should not be used to write off the technology itself.
(as a side note, I do have issues with how training data is gathered without consent of its creators, but that’s a separate concern from its application)
Isn’t this just all what the AI plot of Metal Gear Solid 2 was trying to say? That without context on what is real and what’s not the noise will drown out the truth
I don’t mind the crazy answers as long as they’re attributed. “You can use glue to stop cheese from sliding off your pizza” - bad. “According to fucksmith on reddit [link to post], you can use glue…”. That isn’t so great either but it’s a lot better. There is also a matter of the basic decency of giving credit for brilliant ideas like that.
At least it gave credit to a reddit user when it suggested to a suicidal person that they could jump from the Golden Gate Bridge!
Who doesn’t like getting lawyer PMs because you made a dark joke on a meme subreddit? (Or in future fediverse)
I like how the article slams USB 3.2 vs USB 4.0 but ignores that Google was saying " As of August 202_4_ "… A date that notable has not yet occurred.
Being a bit pedantic here, but I doubt this is because they trained their model on the entire internet. More likely they added Reddit and many other sites to an index that can be referenced by the LLM and they don’t have enough safeguards in place. Look up “RAG” (Retrieval-augmented generation) if you want to learn more.
For people who have a really hard time with #2 (memorable passwords), here’s a trick to make good passwords that are easy to remember but hard to guess.
- Pick some quote (prose, lyrics, poetry, whatever) with 8~20 words or so. Which one is up to you, just make sure that you know it by heart. Example: “Look on my Works, ye Mighty, and despair!” (That’s from Ozymandias)
- Pick the first letter of each word in that quote, and the punctuation. Keep capitalisation as in the original. Example: “LomW,yM,ad!”
- Sub a few letters with similar-looking symbols and numbers. Like, “E” becomes “3”, “P” becomes “?”, you know. Example: “L0mW,y3,@d!” (see what I did there with M→3? Don’t be too obvious.)
Done. If you know the quote and the substitution rules you can regenerate the password, but it’ll take a few trillion years to crack something like this.
- Home Remedies for Appendicitis // If you’ve ever had appendicitis, you know that it’s a condition that requires immediate medical attention, usually in the form of emergency surgery at the hospital. But when I asked “how to treat appendix pain at home,” it advised me to boil mint leaves and have a high-fiber diet.
That’s an issue with the way that LLM associate words with each other:
- mint tea is rather good for indigestion. Appendicitis → abdominal pain → indigestion, are you noticing the pattern?
- high-fibre diet reduces cramps, at least for me. Same deal: appendicitis → abdominal pain → cramps.
(As the article says, if you ever get appendicitis, GET TO A BLOODY DOCTOR. NOW.)
And as someone said in a comment, in another thread, quoting yet another user: for each of those shitty results that you see being ridiculed online, Google is outputting 5, 10, or perhaps 100 wrong answers that exactly one person will see, and take as incontestable truth.
Or, like, use bitwarden or something to do it for you.
Don’t get me wrong, password managers are fucking great. But sometimes you need to remember a password. (Including one for Bitwarden itself.)
Somewhat amused that the guy things “UW” universally means “University of Wisconsin”. There are lots of UWs out there, and the AI at least chose the largest (University of Washington), though it did claim that William Taft was class of 2000.
Even for Wisconsin, UW is the system. There’s UW Lacrosse, UW Milwaukee, UW Madison, UW Platteville, UW Whitewater…
…UW Laramie, UW Seattle…
Oh wait.
It’s a big school, I bet he was. But not THAT William Taft.
Some of the answers are questions?
People get very confused about this. Pre-training “ChatGPT” (or any transformer model) with “internet shitposting text” doesn’t cause them to reply with garbage comments, bad alignment does. Google seems to have implemented no frameworks to prevent hallucinations whatsoever and the RLHF/DPO applied seems to be lacking. But this is not “problem with training on the entire web”. You can pre-train a model exclusively on a 4-chan database that with the right finetuning you would see a perfectly healthy and harmless model. Actually, it’s not bad to have “shitposting” or “toxic” text in the pre-training because that gives the model an ability to identify it and understand it
If so, the “problem with training on the entire web” is that we would be drinking from a poisoned well, AI-generated text has a very different statistical distribution from the one users have, which would degrade the quality of subsequent models. Proof of this can be seen with the RedPajama dataset, which improves the scores on trained models simply because it has less duplicated information and is a more dense dataset: https://www.cerebras.net/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama
Credit where credit is due, if we define a generation as a 15 year period of time, and we decide that Gen Z started in 1995 (for easy math), you do, in fact, land on 1665.
I don’t know why the author thinks that Gen D doesn’t exist yet, when the pattern of X, Y (Millennials), and Z make a pattern that both implies that the Latin alphabet’s use is coming to an end for this purpose (ignoring that Gen X was named not as part of a sequence of letters, but by Douglas Copeland’s book, which was titled itself using an existing phrase), and that can easily be extrapolated backwards through time.
All this really proves is that it is a complex system and most people can not grasp the complexity and how to use it.
Like if you go searching for entities and realms within AI alignment good luck finding anyone talking about what these mean in practice as they relate to LLM’s. Yet the base entity you’re talking to is Socrates, and the realm is The Academy. These represent a limited scope. While there are mechanisms in place to send Name-1 (human) to other entities and realms depending on your query, these systems are built for complexity that a general-use implementation given to the public is not equip to handle. Anyone that plays with advanced offline LLM’s in depth can discover this easily. All of the online AI tools are stalkerware-first by design.
All of your past prompts are stacked in a hidden list. These represent momentum that pushes the model deeper into the available corpus. If you ask a bunch of random questions all within the same prompt, you’ll get garbage results because of the lack of focus. You can’t control this with the stalkerware junk. They want to collect as much interaction as possible so that they can extract the complex relationships profile of you to data mine. If you extract your own profiles you will find these models know all kinds of things that are ~80% probabilities based on your word use, vocabulary, and how you specifically respond to questions in a series. It is like the example of asking someone if they own a lawnmower to determine if they are likely a home owner, married, and have kids. Models make connections like this but even more complex.
I can pull useful information out of models far better than most people hear, but there are many better than myself. A model has limited attention in many different contexts. The data corpus is far larger than this attention could ever access. What you can access on the surface without focussing attention in a complex way is unrelated to what can be accomplished with proper focus.
It is never a valid primary source. It is a gateway through abstract spaces. Like I recently asked who are the leading scientists in biology as a technology and got some great results. Using these names to find published white papers, I can get an idea of who is most published in the field. Setting up a chat with these individuals, I am creating deep links to their published works. Naming their works gets more specific. Now I can have a productive conversation with them, and ground my understanding of the general subject and where the science is at and where it might be going. This is all like a water cooler conversation with the lab assistants of these people. It’s maybe 80% correct. The point is that I can learn enough about this niche to explore in this space quickly and with no background in biology. This is just an example of how to focus model attention to access the available depth. I’m in full control of the entire prompt. Indeed, I use a tool that sets up the dialogue in a text editor like interface so I can control every detail that passes through the tokenizer.
Google has always been garbage for the public. They only do the minimum needed to collect data to sell. They are only stalkerware.









